概要描述
当在8180页面上发现服务不健康(红色或者黄色)或者未启动(灰色)时,常见的办法是去启动(或者重启)问题服务
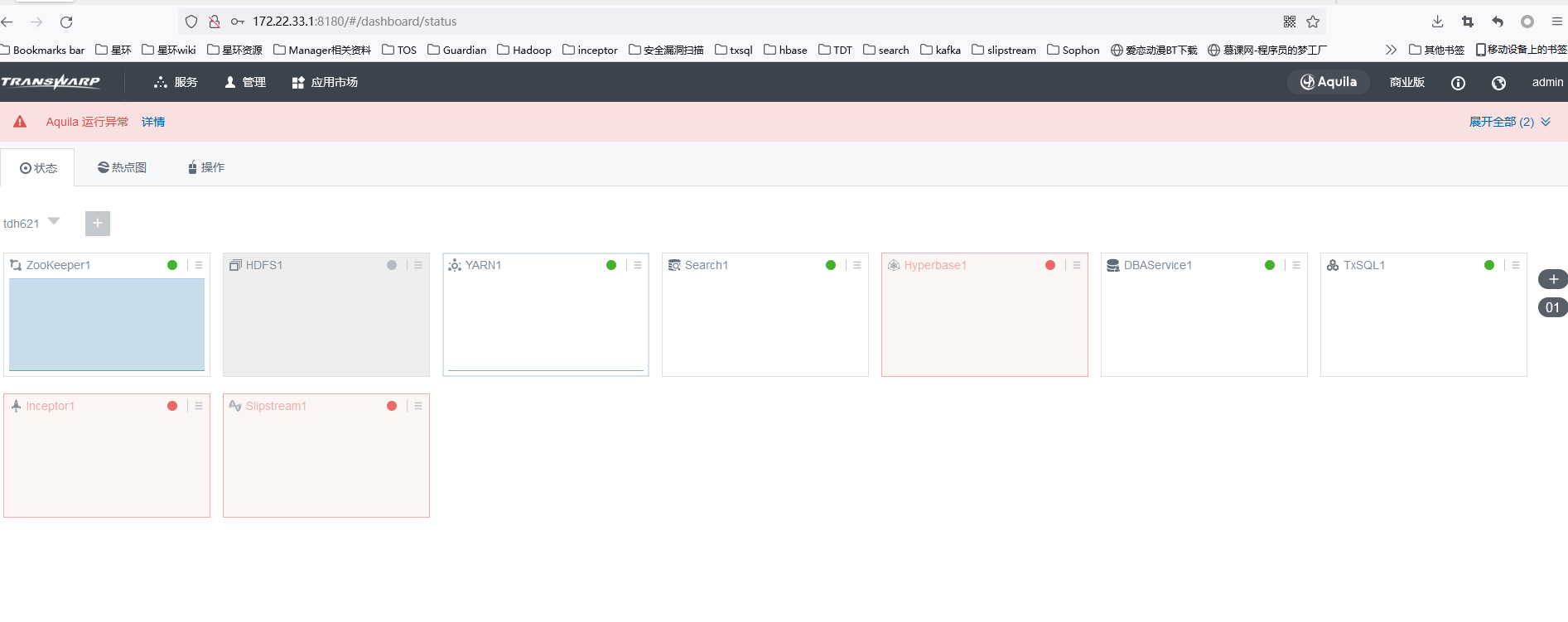
本文主要介绍启动服务失败的时候的一些基本的问题排查步骤
详细描述
TDH 5.X开始实现了容器化,因此服务启动失败时需要检查两个方面: 1,容器相关的服务是否正常 2, 服务本身的进程启动情况
具体的步骤如下
1 集群基础的服务是否健康
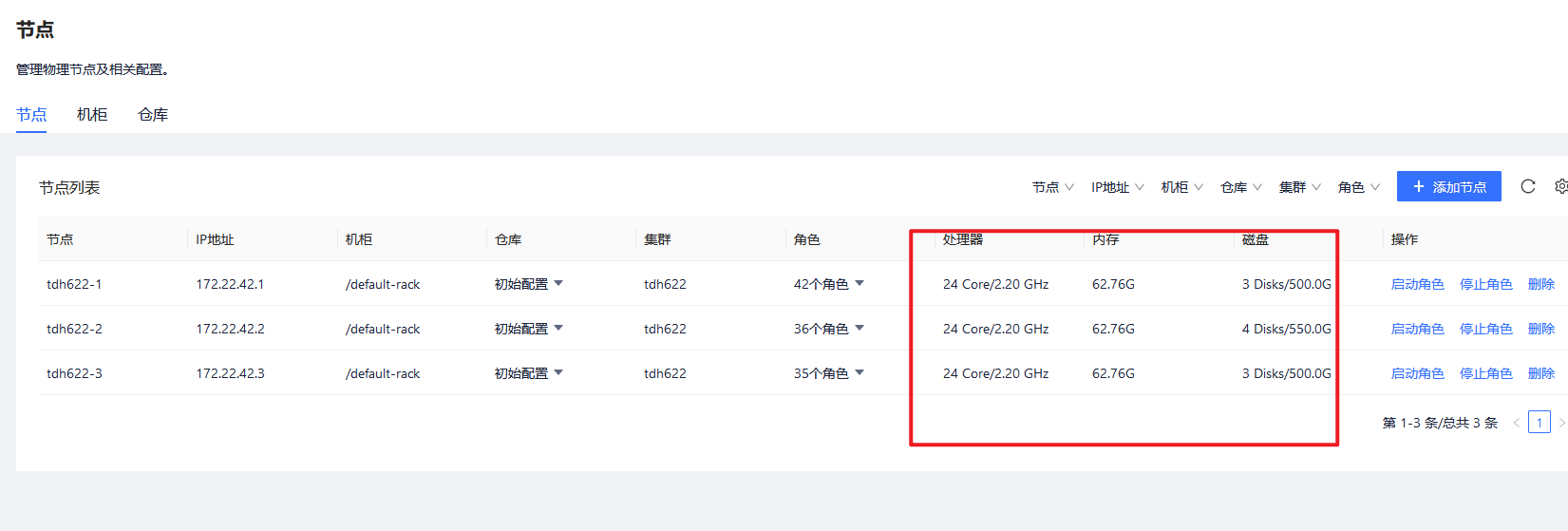
TDH服务的健康依赖于许多的基础组件,当发现启动服务失败时候,请首先检查这些基础服务的健康状态,一般包括transwarp-manager-agent/tos/guardian/许可证等服务
检查方法是:
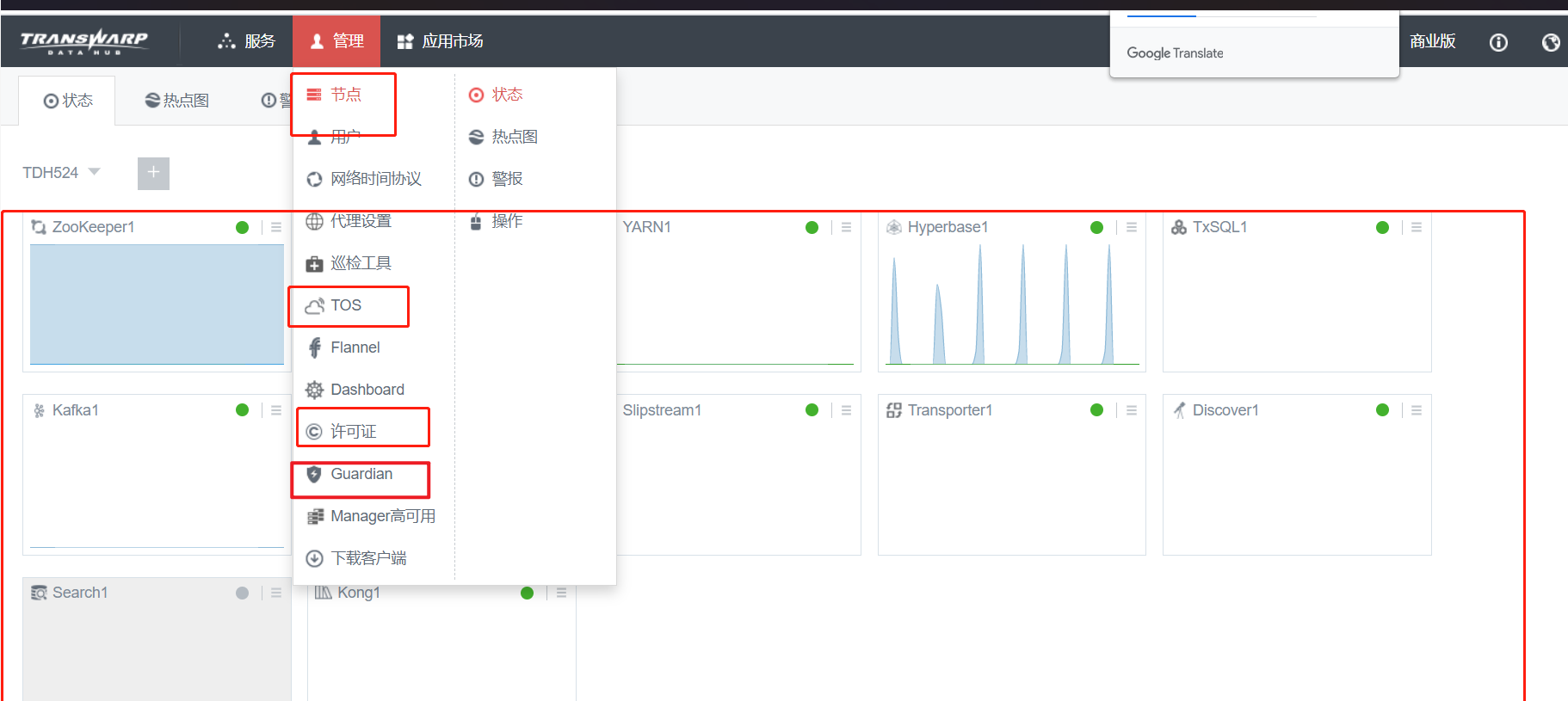
或者是:
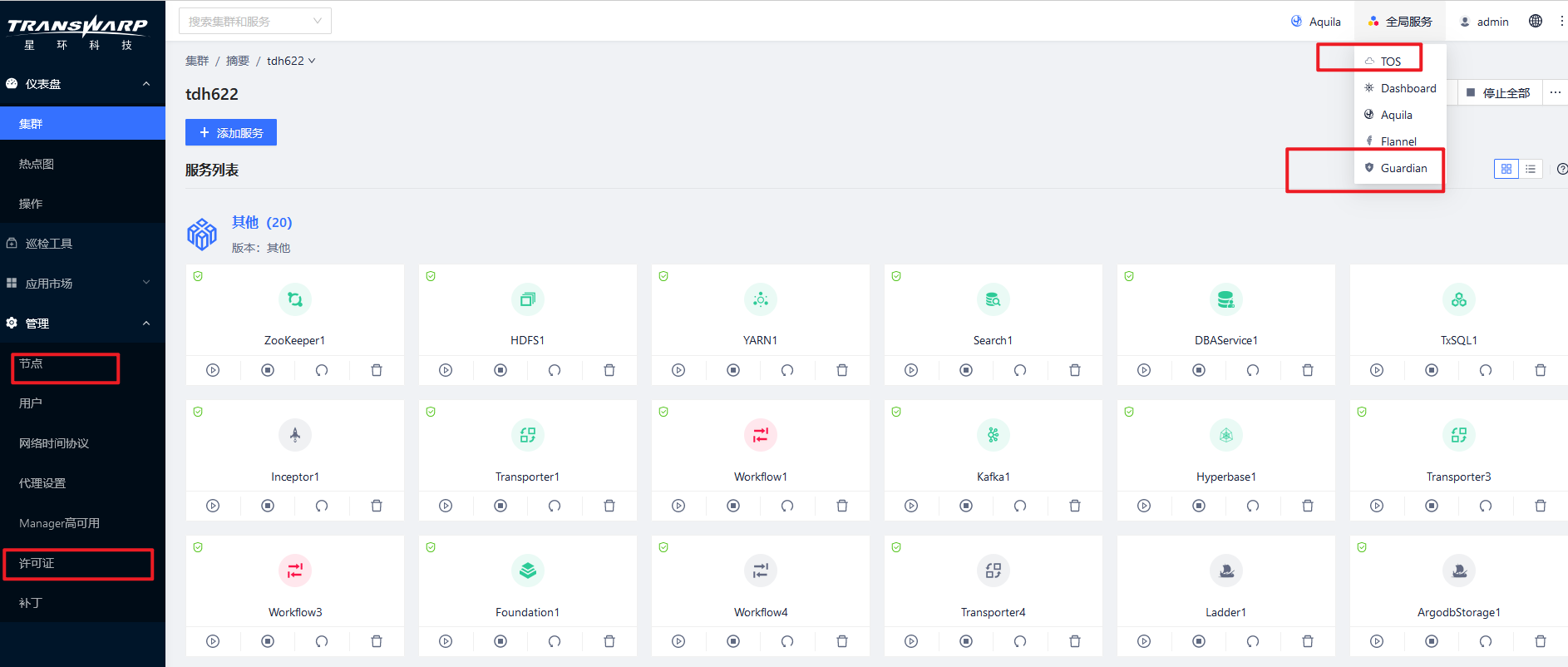
如果有不健康的可以首先通过页面来启动它
其中节点页面上必须要能显示硬件信息才证明是健康的
否则需要ssh登录到对应的服务器上,手动启动一下agent进程:
systemctl restart transwarp-manager-agent
2 查看页面上报错的原因
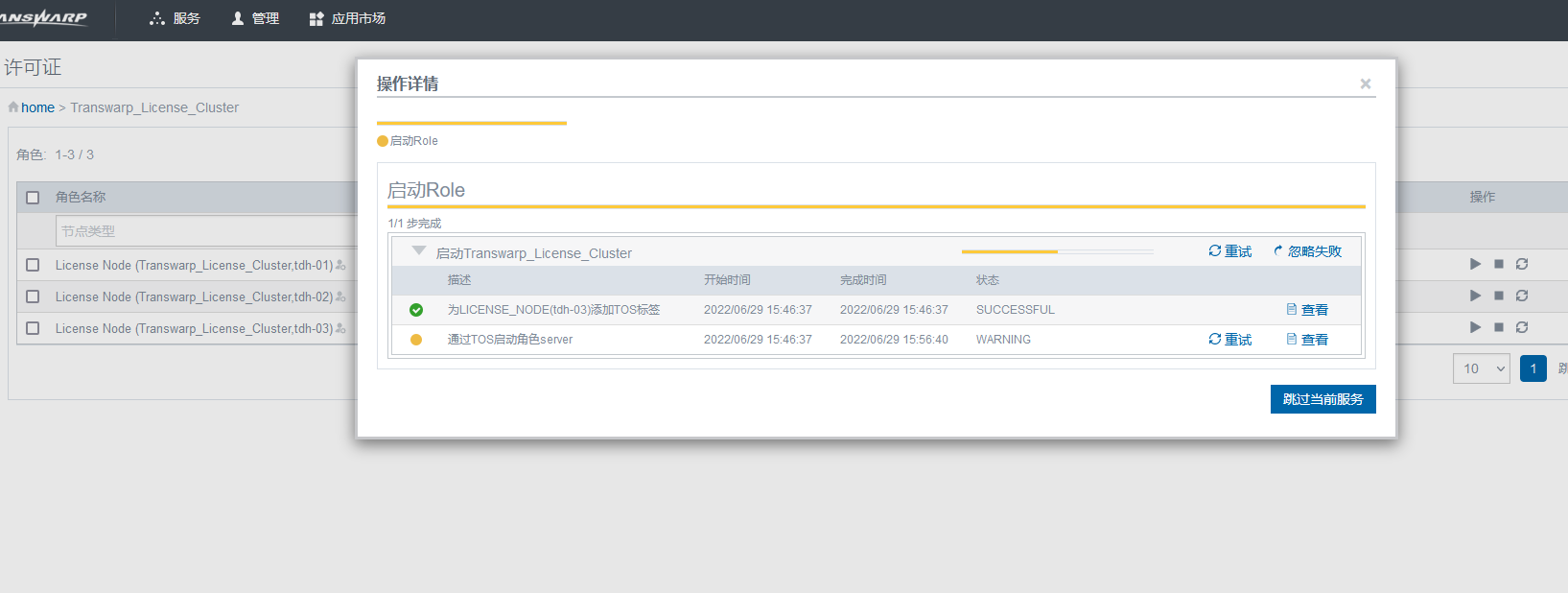
任何一个操作失败的时候,在页面上都会给出对应的输出,所以排查的第一步就是点击“查看”这些输出中的报错:
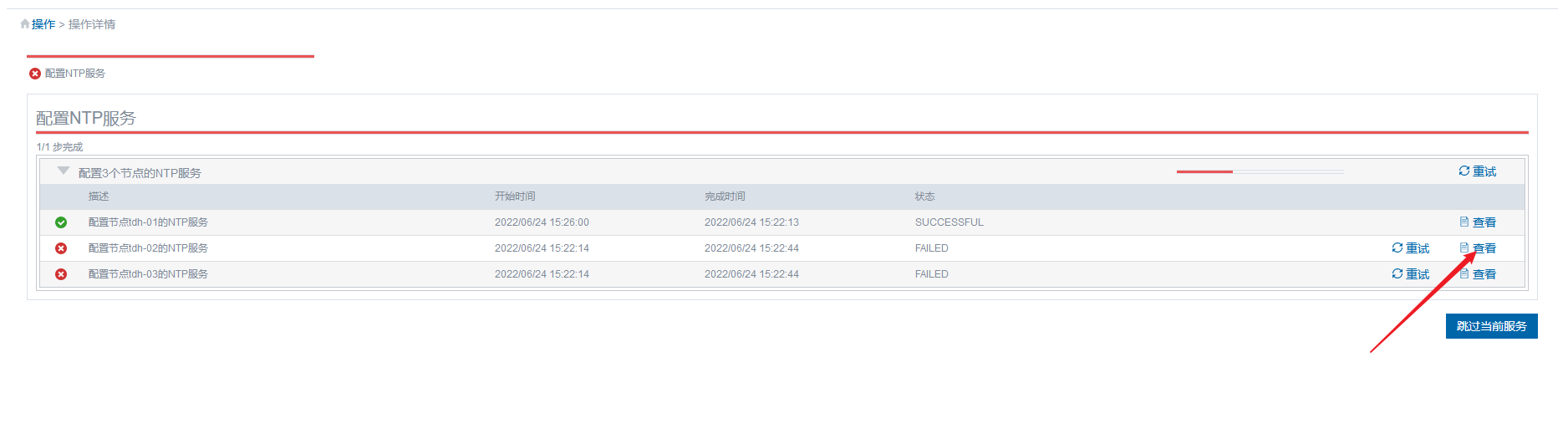
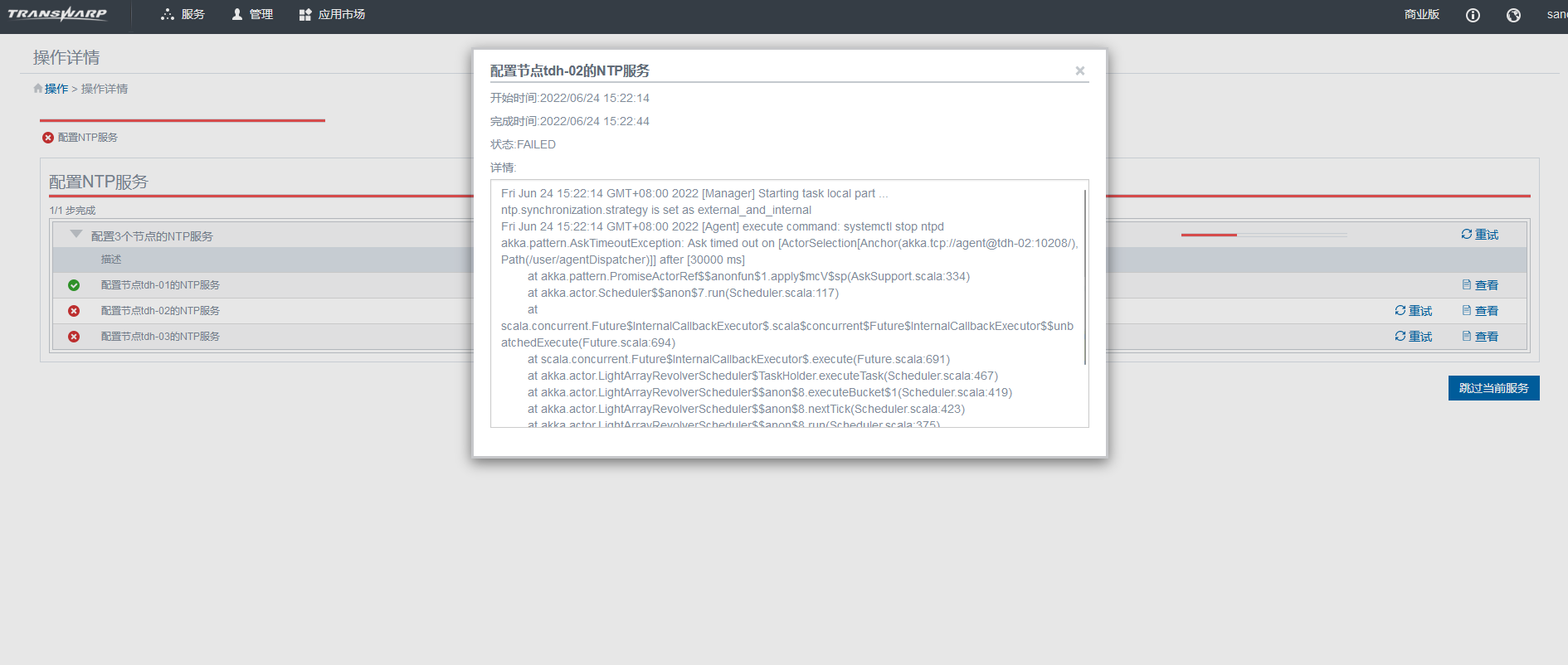
比如上图中的输出就是在提示连接对应节点的10208端口失败了,接下来只要找到这个端口对应的进程把它启动即可。
当然现实往往不会很完美,当遇到的是启动服务失败的情况时,页面上的输出往往不会如此直接指向错误的根源:
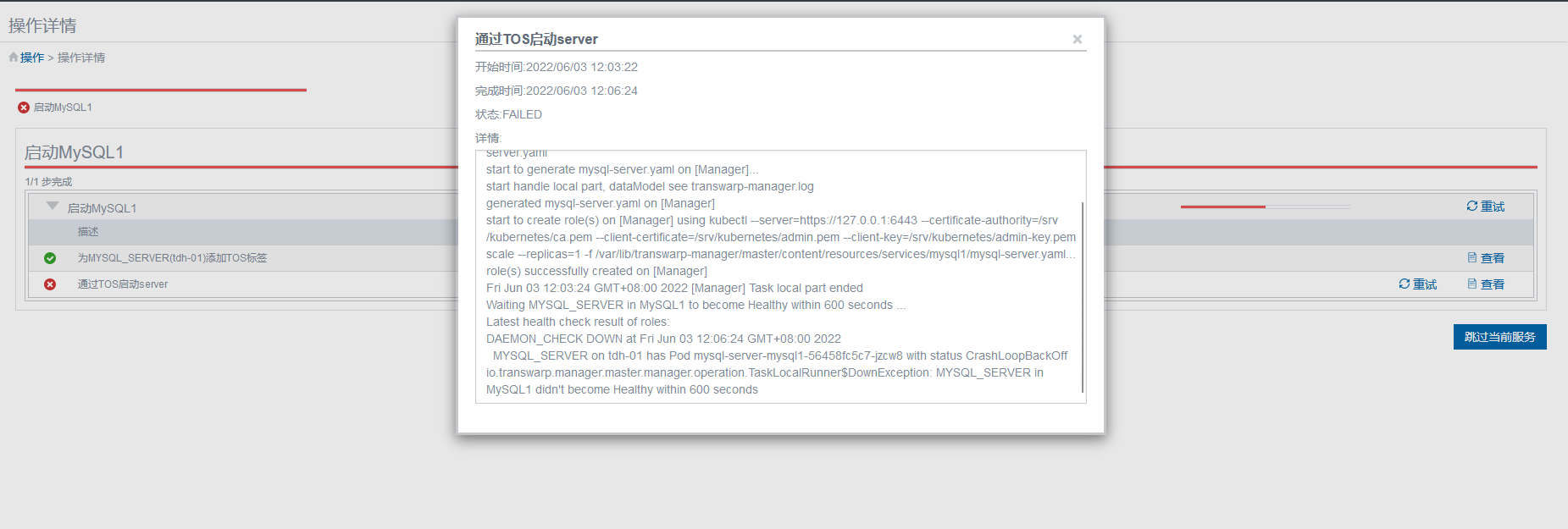
3 查看服务的后台pod状态及日志
在TDH 5.X开始的集群中,所有服务都是容器化的,所以当服务启动失败时候,先检查它的容器pod状态是否正常,比如如果是inceptor服务启动失败,那么可以在后台执行:
kubectl get pod -owide | grep inceptor
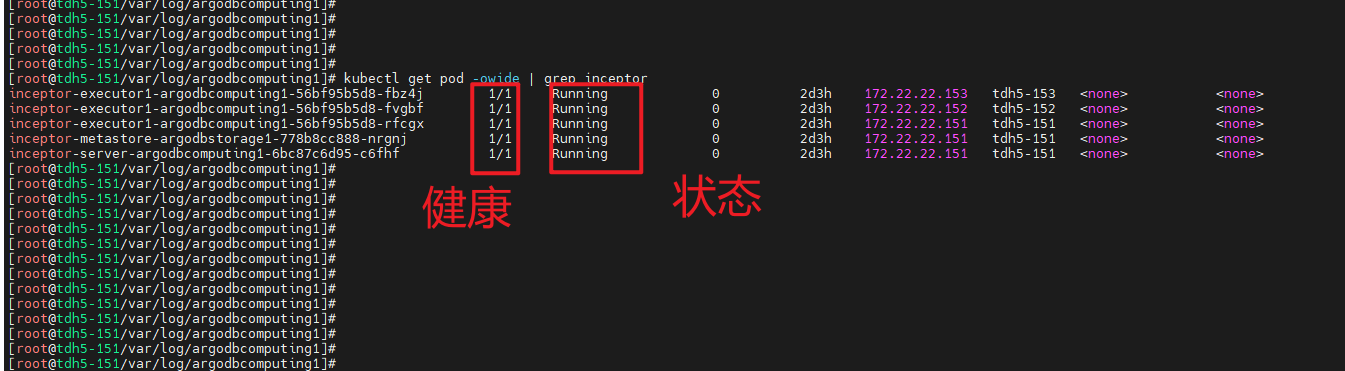
结果中状态必须是running、健康探针必须是1/1时这个pod才是健康的,否则就需要去查看这个pod的日志,命令一般是两条:
kubectl logs <pod名字>
kubectl describe pod <pod名字>
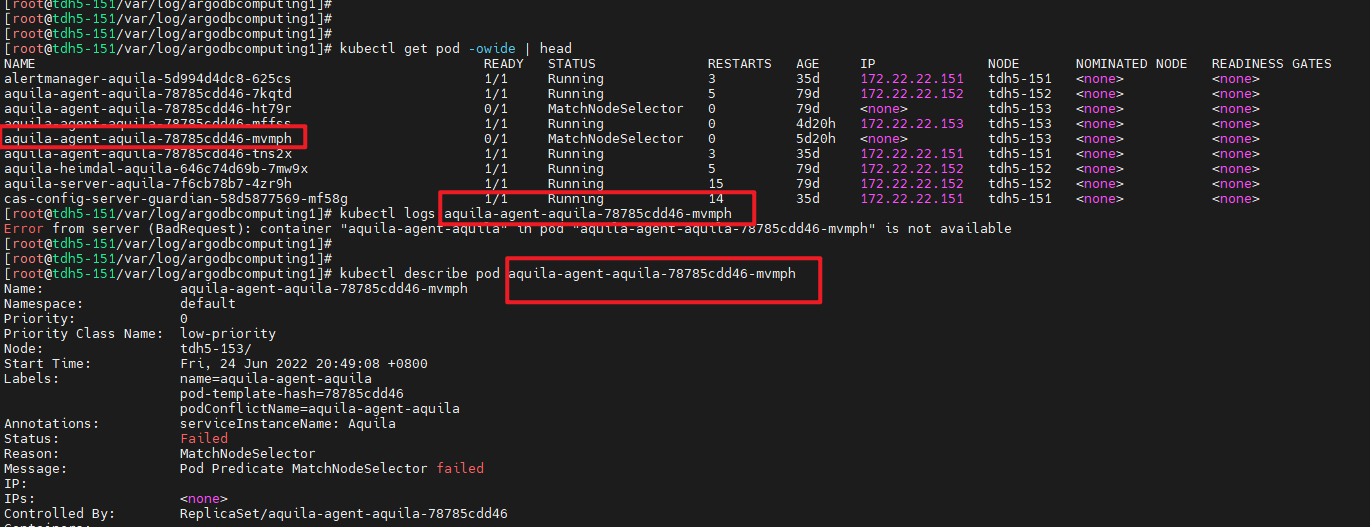
两条命令输出的日志侧重点并不相同,根据结果中的错误信息往往能够对服务启动的原因可以有初步的判定
4 查看服务的日志
如果从pod的日志里还是无法找到错误,可以直接去检查服务的日志,首先g根据上一步的输出结果可以查到问题pod所在的节点

登录到对应的服务器之后,可以到这个路径下查找日志:/var/log/服务名
比如inceptor服务的路径一般都是/var/log/inceptor1/(最后的数字是安装的时候定下的)
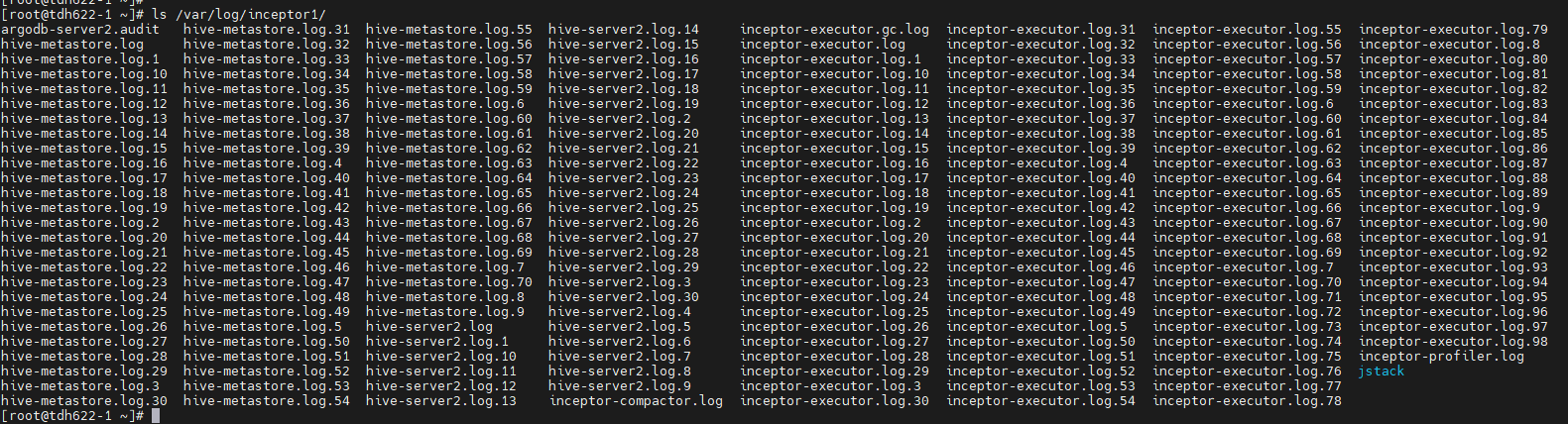
该目录下往往会有多个角色的日志,具体需要查看哪一个文件呢?
一个角色的名字往往都是有一致性的,从pod名跟文件名就可以得出其关联,比如:
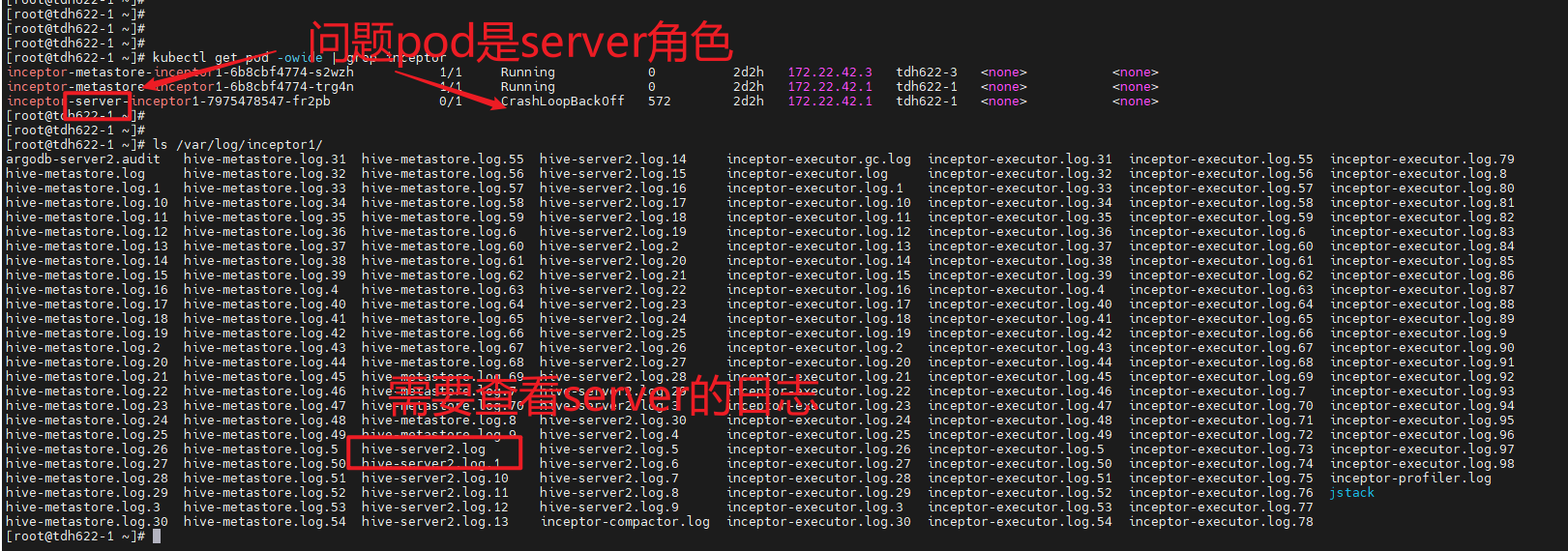
另外TDH服务保留日志的时间比较久、日志文件数往往是有多个,需要注意日志文件中的时间。