内容纲要
概要描述
本文档旨在提供一份 impexp 工具的快速上手指南,有关工具的更详细的配置、使用、原理、注意事项。
工具获取方法:
- ArogDB 3.2.0 开始,集成进TDH-Client,简单配置后可直接使用
- 其余版本可联系星环售后技术支持 通过 https://drive.weixin.qq.com/s?k=ABoAuwfGAAk2aC1njT (企业网盘) 获取
详细说明
1. 准备数据
当前有一张default.people_single_partition_holo表,总数据量1000w。
3.修改配置文件
配置文件在TDH客户端的TDH-Client/impexp/argodb-impexp.properties目录下,重点关注如下备注进行修改
# ====== EXPORT ======
# 待卸载的源路径(一般是HDFS)
argodb.export.repository.sourcedir=/tmp/hive/impexp/export
# 待存储的目标路径
argodb.export.local.targetdir=/tmp/impexp
# 是否导出一个文件,设置为 true导出一个文件
argodb.export.mergeOneFile=false
# If argodb.export.mergeOneFile=true, this property is useful.
argodb.export.local.mergefile.name=single_one.file
# 网络传输的buffersize,默认 1MB
argodb.export.buffersize=1048576
# 下载文件时的并发线程池大小
argodb.export.thread.pool.size=10
argodb.export.thread.pool.queue.size=1000
# 待下载的文件先放入queue中
argodb.export.file.queue.size=1000
# 压缩文件 解压下载时 去掉 压缩后缀
argodb.export.compressfile.remove.suffix=true
# 监听目录时的终结文件,发现该文件,监听结束,下载结束后会自动删除该文件
argodb.export.listen.endfile.flag=_END_.FLAG
# 监听线程的间隔时间
argodb.export.listen.interval.ms=5000
# 监听线程启动时,是否忽视掉目录当前已有的文件,false表示不忽视
argodb.export.listen.init.skipfile=false
# 导出清单文件,如果脚本指定表信息 ,则忽略该参数
argodb.export.list.file=
4.执行导入命令
#首先需要初始化客户端
source TDH-Client/init.sh
#如果是kerberos安全认证的话,需要执行kinit命令
#通过执行argodb_import_export.py结合参数进行调用
python argodb_import_export.py export default.people_single_partition_holo /root/exportDir脚本使用说明:
# 单表
python argodb_import_export.py export ${srcTableName} ${destPath}
# 表清单
python argodb_import_export.py export -Dargodb.export.list.file=export.list
# 表清单文件(expport.list)格式如下
参数说明:
${srcTableName} - 导出的ArgoDB表名(库名.表名 形式)
${destPath} - 导出数据本地路径(工具会在路径下自动按表名再创建一级目录)
例子:
# 将 demo_db.demo_tbl 表中的数据导出到 /demo/data/ 目录
python argodb_import_export.py export demo_db.demo_tbl /demo/data/ 脚本执行日志如下:
ARGODB_IMEXPORT_OPTS=
Analyze argument finished.
========================================
Start export at: [08/08/2022 14:51:42]
========================================
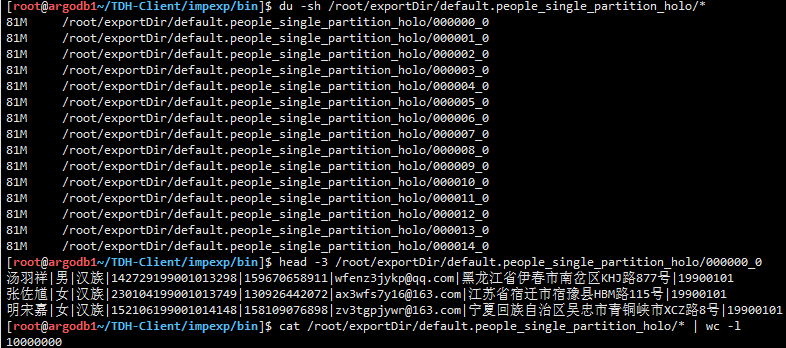
导出表 default.people_single_partition_holo 开始...
为 default.people_single_partition_holo 创建hdfs导出目录
hadoop fs -mkdir -p hdfs://nameservice1/tmp/hive/exportTable/default.people_single_partition_holo
清空目录下数据
hadoop fs -rmr hdfs://nameservice1/tmp/hive/exportTable/default.people_single_partition_holo/*
清理本地table目录
rm -rf /root/exportDir/default.people_single_partition_holo
SQL语句:
INSERT OVERWRITE DIRECTORY 'hdfs://nameservice1/tmp/hive/exportTable/default.people_single_partition_holo' ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LINES TERMINATED BY '
' SELECT * FROM default.people_single_partition_holo;
执行SQL命令:
beeline -u "jdbc:hive2://172.22.23.1:10000/default" -n hive -p 123456 -f default.people_single_partition_holo_1659941508.55_execSQL.sql
删除临时sql文件:default.people_single_partition_holo_1659941508.55_execSQL.sql
执行SQL成功
sql执行用时:225.120579958
执行命令:./impexpTool.sh export hdfs://nameservice1/tmp/hive/exportTable/default.people_single_partition_holo /root/exportDir
下载文件 to /root/exportDir from hdfs://nameservice1/tmp/hive/exportTable/default.people_single_partition_holo spend time 81.9212419987 s
导出表 default.people_single_partition_holo 结束,总用时 312.687378883 s
大致的逻辑其实就是 ArgoDB表 -> HDFS -> 本地文件 这么个过程。
最终检查本地文件的数据完整性,验证通过。